一、什么是分布式调用链路跟踪?
通过对分布式系统中各系统的相互调用数据采集,对调用的开始时间、结束时间、名称、标签等数据进行采集、汇总、分析,通过分析结果对系统进行优化等。
二、为什么需要链路跟踪?
随着由业务发展,系统必然会由单体应用向分布式应用发展,一个请求会涉及到多个子系统间的调用,涉及到多台机器。在现代微服务系统中,复杂程度更甚,客户端的一次请求操作,可能需要经过系统中多个模块、多个中间件、多台机器的相互协作才能完成,并且这一系列调用请求中,有些是串行处理的,有些是并发执行的,那么如何确定客户端的一次操作背后调用了哪些应用、哪些模块,经过了哪些节点,每个模块的调用先后顺序是怎样的,每个模块的性能问题如何?随着业务系统模型的日趋复杂化,分布式系统中急需一套链路追踪(Trace)系统来解决这些痛点。
1、跟踪BUG困难
由于一个客户端请求会涉及到多个服务间的调用,我们再排查BUG的时候需要对请求过程中所有的调用逐个检查,这时候虽然可以去各个系统中查找日志达到目的,但这是非常低效且困难的。这时候如果可以通过一个请求特征一次性筛选出来全部的日志以及响应数据会大大提高我们的工作效率。
2、性能分析困难
为了优化一些响应慢的请求我们往往需要把各各请求的关键节点进行耗时分析,针对每次服务调用进行耗时统计。分散的系统及日志也会导致我们在进行此项工作时困难重重。如果有一个工具可以清晰的看到每次服务调用的耗时与前后顺序,一段时间内耗时排名,将会让这个工作变得轻松很多。
3、服务依赖分析困难
在缺少服务管理的分布式系统中,应用间的依赖情况往往也是模糊和混乱的。通过对应用运行期间的服务调用统计我们其实是可以知道他们之间的依赖关系以及依赖程度的,现在缺少的只是一个统计工具。
三、通过链路跟踪可以做到什么?
数据分析:根据请求产生的时间我们可以清晰的看到服务间的调用次序,通过服务之间的关联可以看到服务调用深度,通过各个关键节点可以计算出来调用耗时,通过大量请求统计可以统计调用依赖。
解决问题:通过查看调用链路,可以清晰的看到在什么位置节点出现错误导致数据出现断路或者在哪个节点的数据出现错误,帮助我们快速的在分布式系统中查找问题节点。通过对近期全部请求进行统计,可以很快的发现耗时最多的客户端请求,并且通过分析客户端请求找到最慢的关键节点,快速的优化请求耗时,提高系统性能,找到系统瓶颈。通过对调用数据的统计还可以理清服务依赖,监控依赖的程度。
四、如何实现链路跟踪?
如果选择自己实现在设计或选项时要考虑几个重要特性:低侵入性,应用透明;低损耗;大范围部署,扩展性。
主要分为以下几个步骤:
1、埋点和生成日志
2、抓取和存储日志
3、分析和统计调用链数据
4、计算和展示
在初期更建议选择开源的成型工具使用,现在有比较多的分布式链路跟踪工具可供选择,用户比较多的有Google的Dapper,Twitter的zipkin,淘宝的鹰眼,新浪的Watchman,京东的Hydra等。考虑到易用性、迭代速度、兼容范围等方面,本文后续以zipkin为例。
五、如何在PHP中使用?
对应新的应用可以使用thrift进行接入,对应技术栈较旧的框架也可以通过http接口进行对接。下面以能兼容大部分php框架的方式进行介绍。
1、实现日志上报处理类
实现思路是通过php的curl将符合zipkin格式的span数据上传到zipkin的http接口。
接口文档:https://zipkin.io/zipkin-api/#/default/post_spans
实现样例:https://www.it603.com/code/56.html
2、在入口文件开始及结束处添加服务器端日志,生成唯一的traceID对请求进行标识。
比如:
TraceLog::info('sr');
//process request
TraceLog::info('ss', array('server_send' => $response));3、在服务调用的http client开始和结束处添加客户端日志,生成本次调用的spanID对调用过程进行记录,并把traceID和spanID传递给其他服务,以供其他服务在记录日志时可以形成一个完整的链路流程。
比如:
TraceLog::info('cs', array("rpc_url" => $url));
//rpc client
TraceLog::info('cr', array('rpc_receive' => $response));4、提高稳定性
我们可以通过引入mq提高性能并且可以避免因链路跟踪系统出现故障影响业务系统。实现思路是将日志写入到mq消息系统内,通过统一的消费者进程将日志写入到zipkin中,此处不再展开介绍。
六、如何使用链路跟踪工具?
zipkin拥有丰富的筛选项我们可以通过服务名、span名称、请求时间、Annotation、请求持续时间等条件进行组合选择,还可以通过服务占比、耗时、时间进行排序。
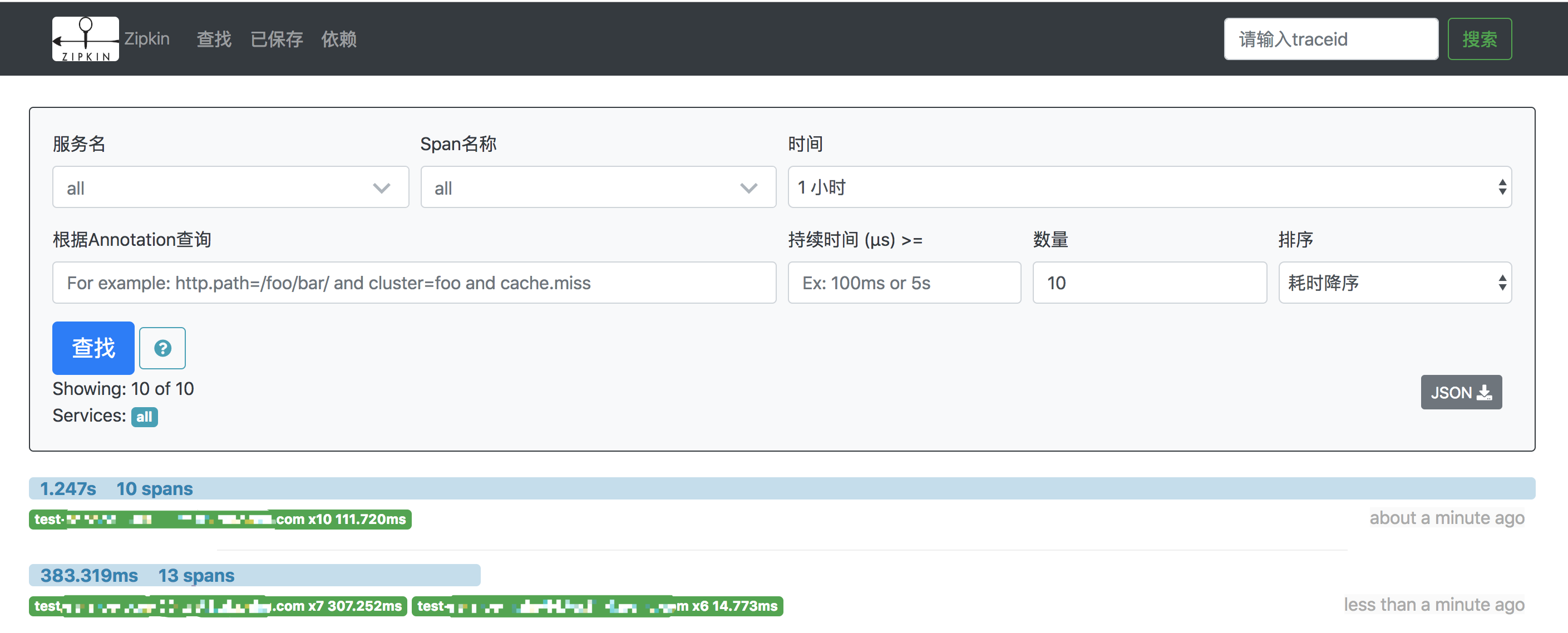
在实际应用中我们可以通过请求的url地址、请求中的traceID、请求产生的时间查找到我们想要的数据。在获取到请求后我们可以看到这个请求下面所有的调用数据。
在进行性能优化时可以根据耗时排序找到最耗时的请求,进入到请求详情后可以看到每一步的耗时。
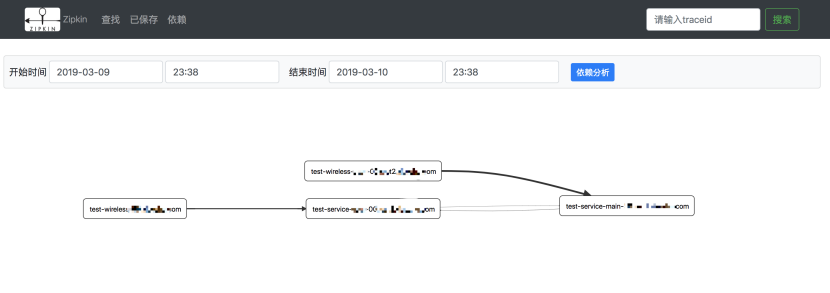
在依赖下面可以看到所有服务的依赖拓扑图,还可以查询到服务间的调用成功次数、调用失败次数等。
参考资料
分布式集群环境下调用链路追踪:https://www.ibm.com/developerworks/cn/web/wa-distributed-systems-request-tracing/index.html
Zipkin快速开始: https://segmentfault.com/a/1190000012342007
zipkin原理与对接PHP: https://juejin.im/entry/5a0957b96fb9a045293641ae
技术
推荐
开发