网络抓取类应用开发入门(一)
- 2014-08-09 21:14:00
- CJL 原创
- 9295
互联网上的信息中web占了很大一部分,因其良好的界面也导致了机器获取信息难度的增加,虽然很多网站都提供JSON、XML等规范格式的数据,但很多情况下没有这种标准格式的数据,需要我们通过各种变通的形式去整理数据,间接获得自己需要的数据,这时就需要类似网络爬虫的简单网络抓取工具了。本文主要结合作者经验介绍几种环境下网络采集工具的开发思路。
应用场景:特定区域信息的采集(如学校新闻、微博等信息整合、天气的定时采集)、博客迁移(博文、留言等采集)、网页信息第三方嵌入(多系统信息集中查询工具)、内容格式准换(编码、编排方式修改)等。
基本的思路就是编程实现网络文本的获取,记录cookie信息实现登陆验证,通过正则匹配截取到特定内容,将截取到的内容进行整合再处理形成需要的信息格式,进行输出或保存(数据库、文件、发送给第三方等)。
作者已有的样例:某高校选课系统客户端(自动化操作)、某高校多站点新闻整合以及编码转换(供其他站点调用)、天气的定时采集、学生信息查询客户端(移动端)等需要源码参考的可以发邮件索取。
实现时看需求选择语言,如需要做成windows客户端可以选择C#,如需要被其他站点引用可以选择PHP、JSP等,如需实现定时任务可配合脚本语言如Python等,如需做移动端则选着相应的移动应用开发平台。总之基本每种编程语言都是可以方便的实现的。本文以PHP开发一个博客迁移应用为例进行开发思路的介绍。
最终效果:如下图,根据设定好的规则进行文章的抓取保存。
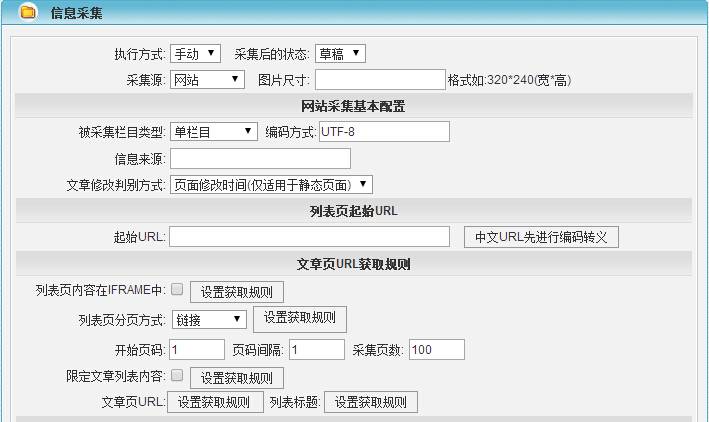
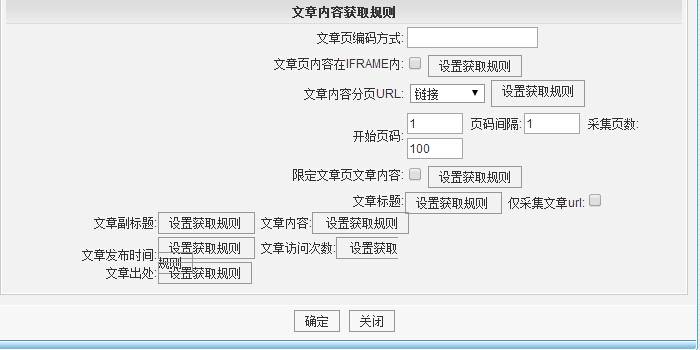
一、实现技术
PHP、正在匹配、数据库操作。
二、实现思路
(1)获得相关的设置参数如列表页地址以及地址的推导规则,获得文章链接的方式,文章内容,文章标题。浏览量等信息的获取规则。暂时不考虑文章的分页。需要注意网页的编码,图片的抓取,图片地址的转换等。
(2)根据列表页规则遍历列表页获得文章页url。
(3)获取文章页的内容对作者等信息进行匹配获取。
(4)对图片等进行准换,图片抓取,引用地址替换等。
三、代码实现
实现环境为禅知企业门户系统的博客迁移插件。
control类的方法为
public function setting()
{
$testResult = '';
if($_POST)
{
$category = $_POST['category'];
$listLink = $_POST['listLink'];
$listLinkNum = intval($_POST['listLinkNum']);
$viewLinkPre = $_POST['viewLinkPre'];
$viewLinkRegex = $_POST['viewLinkRegex'];
$viewLinkFollow = $_POST['viewLinkFollow'];
$titleRegex = $_POST['titleRegex'];
$contentRegex = $_POST['contentRegex'];
if($listLink != '')
{
for($i=1; $i<=$listLinkNum; $i++)
{
$currentListLink = $listLink . $i;
$listContent = file_get_contents($currentListLink);
preg_match_all($viewLinkRegex,$listContent, $res);
if(isset($res[1]))
{
foreach($res[1] as $r)
{
$viewLink = $viewLink = $viewLinkPre . $r . $viewLinkFollow;
$testResult = $testResult . "\r\n" . $viewLink;
$viewContent = file_get_contents($viewLink);
preg_match_all($titleRegex, $viewContent, $titles);
if(isset($titles[1][0]))
{
$title = $titles[1][0];
$testResult .= $title . '\r\n';
}
preg_match_all($contentRegex, $viewContent, $contents);
if(isset($contents[1][0]))
{
$content = '文章内容:' . $contents[1][0];
$testResult = $testResult . $content;
}
//将获得的文章内容存入数据库
}
}
}
}
$this->view->category = $category;
$this->view->listLink = $listLink;
$this->view->listLinkNum = $listLinkNum;
$this->view->viewLinkPre = $viewLinkPre;
$this->view->viewLinkRegex = $viewLinkRegex;
$this->view->viewLinkFollow = $viewLinkFollow;
$this->view->titleRegex = $titleRegex;
$this->view->contentRegex = $contentRegex;
$this->view->testResult = $testResult;
}
$this->display();
}
view代码:
<div class='panel'>
<div class='panel-heading'>
<strong><i class='icon-building'></i><?php echo $lang->crawler->crawler;?></strong>
</div>
<div class='panel-body'>
<form method='post' >
<table class='table table-form'>
<tr>
<th ><?php echo $lang->crawler->category;?> </th>
<td colspan='2'><?php echo html::input('category', isset($category) ? $category : '')?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->listLink;?> </th>
<td ><?php echo html::input('listLink', isset($listLink) ? $listLink : '');?></td>
<td class='text-info'><?php echo $lang->crawler->listLinkInfo;?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->listLinkNum;?> </th>
<td colspan='2'><?php echo html::input('listLinkNum', isset($listLinkNum) ? $listLinkNum : '');?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->viewLinkPre;?> </th>
<td colspan='2'><?php echo html::input('viewLinkPre', isset($viewLinkPre) ? $viewLinkPre : '');?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->viewLinkRegex;?> </th>
<td colspan='2'><?php echo html::input('viewLinkRegex', isset($viewLinkRegex) ? $viewLinkRegex : '');?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->viewLinkFollow;?></th>
<td colspan='2'><?php echo html::input('viewLinkFollow', isset($viewLinkFollow) ? $viewLinkFollow : '');?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->titleRegex;?> </th>
<td colspan='2'><?php echo html::input('titleRegex', isset($titleRegex) ? $titleRegex : '');?></td>
</tr>
<tr>
<th ><?php echo $lang->crawler->contentRegex;?> </th>
<td colspan='2'><?php echo html::input('contentRegex', isset($contentRegex) ? $contentRegex : '');?></td>
</tr>
<tr>
<th> </th><td colspan='2'><?php echo html::submitButton();?></td>
</tr>
<tr>
<th> </th><td colspan='3'><?php echo html::textarea('', isset($testResult) ? $testResult : '', 'height=100px');?></td>
</tr>
</table>
</form>
</div>
</div>
全部代码可以邮件索取:chujilu1991@163.com
由于时间问题仅将大致的实现思路代码实现,后续的编码基本都差不多。



